YaCy : un moteur de recherche peer to peer sous licence libre pour remplacer Google
C’est ma découverte du jour que je dois à Twitter et plus particulièrement à @glenux. Ce qui me permet au passage de me dire que je devrais peut-être tenter l’expérience de ne plus lire mes centaines de flux RSS et de ne faire que suivre les liens poussés par les personnes que je suis sur identi.ca et twitter. Ce n’est pas la première fois que des informations pertinentes remontent ainsi alors qu’elle ne sont jamais apparues dans les flux RSS que je suis.
En effet de YaCy, je n’avais encore jamais entendu parler bien qu’il existe depuis 2006. Pourtant, l’idée de pouvoir disposer d’un moteur de recherche décentralisé m’avait déjà traversé l’esprit, mais sans en trouver une implémentation utilisable.
A la lecture de la présentation de YaCy, il y a de quoi être emballé. Tout d’abord et c’est à mes yeux une qualité essentielle il est distribué sous licence libre GPL.
Ensuite, ce sont les caractéristiques techniques qui m’emballent :
- Une instance de YaCy peut stocker plus de 20 millions de documents.
- Partage d’index en peer to peer : YaCy implémente un système de partage d’index s’apparentant à un mécanisme de peer to peer (P2P). Ainsi, une instance de YaCy partage son index avec d’autres pairs le rendant ainsi résistant à certaines formes de censures tout comme le partage de fichier P2P est résistant à la suppression de fichiers.
- La possibilité bien entendu d’exécuter votre propre portail de recherche sur votre poste en local ou sur un serveur dédié. YaCy est disponible pour les environnements GNU/Linux, mais aussi pour Windows. Il est écrit en Java ce qui explique cette portabilité.
- Confidentialité de vos recherches : elles sont effectuées sur votre instance YaCy et ne sont donc communiquées à personne.
YaCy se décompose en quatre modules : un web crawler (le processus qui parcourt les pages web à indexer), un moteur d’indexation, une base de données et une interface utilisateur.
Concernant la base de données embarquée, elle est spécifique à YaCy et utilise une structure de type AVL-Trees.
Mais d’un point de vue pratique, cela donne quoi ?
Je suis donc allé consulter le wiki pour voir si je trouvais de quoi installer YaCy. Je vous conseille de rester sur la version anglaise ou allemande du wiki, il y a en effet peu de contenu en langue française.
J’ai trouvé la documentation de l’installation de YaCy sur Debian. Elle est on ne peut plus simple et en cinq minutes à peine, je peux me connecter à l’interface web de yaCy par l’URL http://localhost:8080. Attention cependant l’installation de YaCy nécessite un runtime Java en version 1.5 minimum.
Lors du premier lancement, un écran vous propose de configurer la façon dont vous souhaitez utiliser votre moteur de recherche :
- en mode pair-à-pair ou communautaire,
- en mode autonome : vous décidez des portions du web que vous souhaitez indexer,
- en mode local : vous vous appuyez alors sur des pages web stockées localement.
En mode pair-à-pair, il vous faut définir un nom pour votre instance et également ouvrir le port 8080 pour permettre à d’autres pairs de se connecter.
Le logiciel propose une page de recherche simple et sobre

Vous remarquerez qu’il est possible de rechercher du texte, des images, des fichiers audio, vidéo ou des applications. On retrouve la possibilité d’indiquer le site sur lequel on souhaite effectuer sa recherche avec une syntaxe du type « mot site:le_site.com ».
Bref à peu près l’essentiel de ce que l’on demande en général à un moteur de recherche. Les résultats sont présentés de façon classique avec des petits boutons vous permettent d’enregistrer une URL dans les favoris du logiciel, mais aussi de « voter » pour indiquer la pertinence du résultat à l’aide d’un petit plus vert et d’un moins rouge.
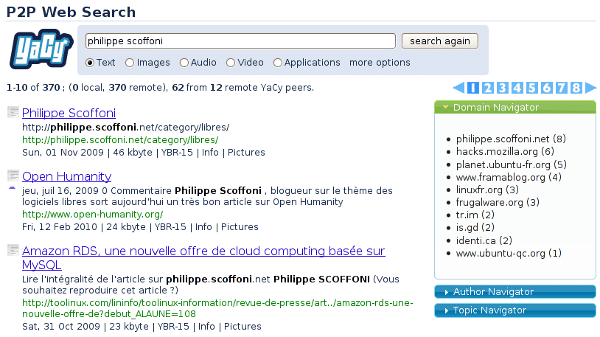
Vous remarquerez la possibilité qui est offerte à partir du résultat d’une recherche de l’affiner en sélectionnant un domaine particulier ou un mot-clé ou encore une notion d’auteur que je n’ai pas très bien comprise. Pour les plus geek, une interface plus sophistiquée est également disponible. Cependant, elle ne m’a pas semblé totalement opérationnelle. YaCy n’a pas peur de la comparaison, puisqu’il propose une recherche avec un double affichage vous permettant de comparer ces résultats avec ceux d’un autre moteur de recherche.
L’interface d’administration est rustique, mais efficace et bien organisée. Elle permet de configurer tous les aspects du fonctionnement du logiciel, mais aussi de suivre de façon très détaillée l’activité des différents processus.
Je me suis livré à quelques tests avec l’instance que j’avais installé sur mon serveur virtuel Gandi. Bien que ne disposant que de 2 parts soit l’équivalent des 2/3 d’un core d’un processeur et de 512Mo de RAM, YaCy a fonctionné avec des temps de réponse acceptable bien que le load average de mon serveur soit monté jusqu’à plus de 8 sur certaines recherches. Si vous prévoyez de l’utiliser durablement, ne soyez pas trop mesquin sur la puissance CPU.
Quant à la pertinence des résultats, difficile de l’estimer dans l’immédiat. Les résultats retournés sont très différents de ceux d’un Google et parfois moins bon. Cependant si cela me permet de me passer de google et de son moteur de recherche pour 80% de mes besoins alors un grand pas aura été franchi. De plus, je n’ai pas encore exploré toutes les possibilités du moteur ni indexé aucun contenu. J’éviterais donc de porter un avis définitif sur ce point. Si vous avez pu vous aussi tester ce moteur de recherche, votre avis sera le bienvenue en commentaire.
Il n’en demeure pas moins que je reste séduit par cette découverte qui représente à mes yeux l’archétype du moteur de recherche de demain. Reposant sur le système du pair-à-pair, c’est l’extension du nombre de noeuds qui permettra d’améliorer les résultats ainsi que la quantité de données indexées, alors si vous le pouvez n’hésiter pas à participer au réseau. Personnellement, je vais laisser tourner cette instance quelques temps pour voir si je parviens à me passer de Google dans mes recherches quotidiennes en espérant que mon serveur tienne le choc.






Très intéressant bien plus qu’une simple alternative à Google
J’ai eu l’occasion de tester YACY. L’idée est séduisante en effet mais le résultat me semble assez lourd à l’utilisation. L’indéxation notamment demande pas mal de ressources.
Mais un gros inconvénient pour moi est le temps de réponse de YACY : à chaque recherche l’architecture P2P nécessite de consulter plusieurs bases de données décentralisées, ce qui prend peu de temps mais trop pour un usage quotidien de la recherche web.
Une architecture de ce type peut-elle réduire ce temps de réponse? Même si je n’y crois pas trop je l’espère car sans cela YACY restera un gadget de geek.
Je test ca demain. Ca a vraiment l’air tres interessant. Jusqu’a présent j’utilisais ixquick mais YaCy a l’air bien mieux.
Il y a aussi le projet Seeks qui a un bon potentiel :
C’est intéressant, merci !
Intéressant… quand je ne serais plus en « chine » (comprenez Citée U de Paris X Nanterre) je m’en installerai un…
Bonjour,
Peut-être lourd pour le moment mais c’est le genre de système qui peut s’alléger énormément avec la multiplication des participants. Le contraire de Google qui est obligé d’avoir des serveurs de plus en plus balèzes.
Excellent comme alternative. Et concernant les problèmes de ressources, je pense que c’est le genre de logiciel qu’on peut facilement mettre en place sur un petit serveur local à la maison. Ca permet à tout le réseau local d’utiliser ce système et de ne pas souffrir des performance nécessaires (étant donné que ça tourne sur une autre machine).
Ceci dit, même si aujourd’hui c’est lent, comme le dit Gégé, ça ne peut que s’améliorer. Donc longue vie à ce genre de projets …
Et sur ce je m’en vais l’installer chez moi 😉
Ca me semble pas mal mais je suis dessus de ne pas avoir wikipedia.org en premiere ligne lorsque je tape le mot clé « Wikipedia ». J’ai esseye aussi « wikipedia website », rien à faire je n’ai que des liens sur des articles.
Le moteur de recherche je l’utilise souvent pour ça, quand je n’ai pas le favoris, je tape sous google et j’ai le site au premier plan. Voir avec la fonction « j’ai de la chance », je peux meme y acceder directement.
Alors Yacy au quotidien, je ne pense pas… De temps en temps pour diversifier les recherches sur un thème, pourquoi pas.
Ou peut etre que mon robot n’a pas encore ete sur la page d’acceuil ?
Comment fonctionne le pageranking ? est-ce un melange avec les digg-like ou il faut cliquer sur « + » pour bien et « – » pour pas bien ? Ce n’est donc pas automatique ?
J’ai arrété YaCy sur mon (trop) petit serveur. Retour sur le PC local. Il va falloir configurer un peu pour passer le routeur et laisser entré les connexions extérieures.
@yacydoa : je n’ai pas encore regardé en détails le fonctionnement de ce moteur. Le + et le – sont a rapprocher des fonctions de Google pour faire « monter » un résultat dans la page de résultat et coupler à un ranking programmé, un ranking plus « humain ». Mais c’est vrai que les résultats qui remontent sont différents. Le réseau public de YaCy n’est à mon avis pas encore assez étendu pour être équivalent à celui d’un Google. En 2008, Google utilisait 2 000 000 de serveurs. Avec un réseau pair à pair c’est pas in-envisageable. Mais faut vraiment que tout le monde s’y mette… Et ce jour là, on peut imaginer que la communauté de développeurs sera tellement nombreuse, que Google nous donnera la même impression que YaCy aujourd’hui : peut mieux faire.
Je sais, je rêve peut-être, mais il le faut bien de temps en temps 🙂
Il y a effectivement le projet seeks cité plus haut. Il a le mérite d’avoir un nom explicite…
J’ai toujours pas trouvé ce que voulait dire YaCy (et puis ça commence pas comme Yahoo…)
« Le Yáwa, est le jaguar mythique qui lutte contre Yacy, l’astre lune pour le manger (si cela arrive, c’est l’éclipse). »
Ca m’a l’air d’etre de la mythologie argentine, à noter aussi un barrage argentin appelé yacyreta, il y a peut etre un lien.
Bonjour,
Ce qui est indispensable, c’est d’avoir en français, l’explication de la configuration par exemple pour le web crawl. Je lis un peu l’anglais mais là je n’y comprends rien.
Qu’en est-il des mots de passe que l’on affiche alors que le crawl est en fonction ?
Faire une option pour démarrer automatiquement Yacy avec Windows.
J’avais pensé à un système pour faire un classement facile des pages. En prenant la taille des polices des différents mots, on arriverai à classer les pages en partant du site primitif jusqu’au autres sites.
Par ce qu’en général, prenons la page de Wikipédia sur mettons le lion. La taille des polices est proportionnelles à la place qu’a le mot dans l’exposé. (bon peut-être c’est déjà utilisé, ce qui ne me parait normal).
Intéressant aussi le projet Seeks. Je me demande comment Weave va se positionner par rapport à ce projet, car à l’origine il était un peu question de la même chose, et ils en ont reparlé depuis peu :
« Future APIs will provide third-party web sites and applications the ability to request permission and obtain explicit access only to specific user data to augment a users’ Web experience, e.g. providing personalized recommendations based upon a user’s bookmarks or search history. »
(source :
Je verrais un avantage au fait de reposer sur Weave pour faire ce genre de choses : tout le monde n’a pas les compétences ou la possibilité de laisser tourner 24h/24 un serveur accessible en intra comme en extra, afin de retrouver et d’enrichir ses données partagées où qu’on soit.
YaCy présente d’ailleurs le même problème : je pense à son système interne de bookmark, mais surtout le simple fait de plusser ou moinsser les liens se doit d’être centralisé.
Or, si je prends mon cas en exemple, ma connexion est très instable et peut ne pas fonctionner quelques heures… ou quelques jours (pire, si la connexion est en rade, la fonction routeur du modem aussi…). Un temps j’avais mis en place un petit serveur web pour retrouver mes signets de partout, mais j’avais vite abandonné à cause de ce problème.
RE. Après avoir installé et vu un peu le fonctionnement je me pose la question suivante : comment empêcher mon pc avec ce système d’être un annuaire pour liens pornographiques ou même d’agressions sexuelles sur des enfants ou autre saloperies ?
Donc très bien ce truc mais avec un contrôle sur les liens. D’ailleurs libre à chacun d’activer des contrôles et le type de contrôle. Qui d’ailleurs n’auraient rien à voir avec un contrôle d’état qui lui déciderait pour tous.
Y’a pas un forum quelque part ? J’ai rien trouvé en français sur google.
http://grub.org/ existe depuis 2000 et servait à wiki search: http://en.wikipedia.org/wiki/Wikia_Search – qui n’a malheureusement pas duré très très longtemps…
@gégé : la communauté française ne semble pas vraiment encore existée autour de YaCy…
@Robin : merci pour le lien. Dommage effectivement pour wikia_search…
je ne connaissais pas cela a l’air sympa
je vais répondre un tout petit peu à coté
j’ai vu sur un autre blog quelqu’un qui essayait de faire sans google
et le gars racontait qu’il avait un peu galéré mais qu’il avait trouvé des sites et des infos
qu’il n’aurait jamais trouvé autrement
je vais essayer de vous retrouver l’article
tout ça pour dire qu’il existe une vrai alternative à Google
et qu’elle existe déja
Combien sommes nous à avoir eu cette idée la ? 😉
Tant pour lutter contre l’hégémonie de gogole que d’économiser les ressources et faire des économies d’énergie …
Reste que si une telle application est intéressante, si chacun doit s’emmerder a paramétrer, etc ça ne passionnera que le geeks …
Maintenant si cette appli se retrouver par exemple dans un plugin pour Firefox, Opera … ça serait déjà mieux …
Mieux encore … que l’appli soit directement dans les box de nos FAI …
On pourrait aussi envisager un plugin pour des cms comme WordPress, Joomla, Drupal …
La il y aurait du monde qui s’y mettrait …
Si l’idée vous plait … transmettez a qui de droit 😉
@Bonob0h : je ne sais pas pourquoi, mais je ne compterais pas trop sur nos FAI qui hadopisent leur box actuellement. Par contre j’aime bien l’idée du plugin.
@philippe
Bien sur que rien n’est gagné avec les FAI 😀
Mais qui ne tente rien n’a rien …
Reste que derrière Yaci il y a une entreprise ou pseudo entreprise … ça serait mieux si c’était structurellement une association/fondation
Sinon pour les plugin pour navigateurs et CMS … bah que dirais tu de lancer un appel a mobilisation 😉
Pour les navigateurs çà semble prévus … mais je pense que pour les CMS ça serait aussi très bien pour les recherche interne sur un site … techniquement et pour en faire la promo … que pour développer un réseau et une mobilisation …
J’en profite pour ajouter le lien pour la version française du wiki dans la mesure ou même si elle est moins complète elle peut aider les non-anglo/germano/phones à mieux comprendre
Bonjour.
Je viens juste de découvrir ce blog et c’est mon premier sujet lu.
Mais j’ai déjà une question: après un mois d’utilisation une idée un peut plus précise ?
Des retours d’utilisation ?
Merci.
Question pour l’auteur de l’article évidement.
@Lim-DûlNo : j’ai arrété de m’en servir pour l’instant. Comme je le disais plus haut, j’avais du l’arrêter sur mon hébergement car il prenait trop de ressource. Sur mon PC, j’ai eu des soucis pour le configurer pour passer le routeur. Pas moyen de faire passer les connexions entrantes malgré la configuration de translation de port faite sur ma freebox. Du coup je continu de Googler quand je peux pas faire autrement (assez souvent il faut bien le dire). Je vais aussi tester seeks mais qui est assez différent dans le concept :
Bonjour,
Je découvre aussi ton blog (via identi.ca) et je commente donc un peu sur le tard.
J’utilise YaCy dans ma boite comme moteur de recherche interne (pas de liens ni synchro vers l’extérieur). Je dois dire que je suis très satisfait des résultats, notamment l’indexation des PDF, documents office (doc, odt, …). C’est le meilleur que j’ai trouvé pour le moment.
Par contre, c’est effectivement assez lourd, mais notre serveur tient bien la charge. Vive Java… Attention à l’indexation de sites aux multiples liens croisés comme scuttle (un del.icio.us-like): le crawler s’emballe et tourne en bourrique.
Voilà pour mon retour d’expérience.
A+
@cjlano : Merci pour ce retour d’expérience
Notez que vous pouvez utiliser YaCy en proxy web, soit en utilisant l’adresse de proxy manuelle 127.0.0.1:8080 au par un mode proxy automatique décrit sur le wiki. Ainsi toutes les pages que vous visitez seront indexé automatiquement par YaCy.
je n’avais pas vu cette possibilité, c’est intéressant en effet, merci pour l’info